
Java XML解析 - 利用dom(org.w3c.dom)解析XML
org.w3c.dom由W3C提供的接口,它将整个XML文档读入内存,构建一个DOM树来对各个节点(Node)进行操作。它将XML看做是一颗树,DOM就是对这颗树的一个数据结构的描述,但对大型XML文件效果可能会不理想。
简介
1. DOM的全称是Document Object
Model,也即文档对象模型。在应用程序中,基于DOM的XML分析器将一个XML文档转换成一个对象模型的集合(通常称DOM树),应用程序正是通过对这个对象模型的操作,来实现对XML文档数据的操作。通过DOM接口,应用程序可以在任何时候访问XML文档中的任何一部分数据,因此,这种利用DOM接口的机制也被称作随机访问机制。
2. 适用范围:小型 XML 文件解析、需要全解析或者大部分解析 XML、需要修改 XML 树内容以生成自己的对象模型。
Dom基本对象
1. Document对象
Document对象代表了整个XML的文档,所有其它的Node,都以一定的顺序包含在Document对象之内,排列成一个树形的结构,程序员可以通过遍历这颗树来得到XML文档的所有的内容,这也是对XML文档操作的起点。我们总是先通过解析XML源文件而得到一个Document对象,然后再来执行后续的操作。此外,Document还包含了创建其它节点的方法,比如createAttribut()用来创建一个Attr对象。主要方法如下:
1. createAttribute(String):用给定的属性名创建一个Attr对象,并可在其后使用setAttributeNode方法来放置在某一个Element对象上面。
2. createElement(String):用给定的标签名创建一个Element对象,代表XML文档中的一个标签,然后就可以在这个Element对象上添加属性或进行其它的操作。
3. createTextNode(String):用给定的字符串创建一个Text对象,Text对象代表了标签或者属性中所包含的纯文本字符串。如果在一个标签内没有其它的标签,那么标签内的文本所代表的Text对象是这个Element对象的唯一子对象。
4. getElementsByTagName(String):返回一个NodeList对象,它包含了所有给定标签名字的标签。
5. getDocumentElement():返回一个代表这个DOM树的根节点的Element对象,也就是代表XML文档根元素的那个对象。
2. Node对象
Node对象是DOM结构中最为基本的对象,代表了文档树中的一个抽象的节点。在实际使用的时候,很少会真正的用到Node这个对象,而是用到诸如Element、Attr、Text等Node对象的子对象来操作文档。Node对象为这些对象提供了一个抽象的、公共的根。虽然在Node对象中定义了对其子节点进行存取的方法,但是有一些Node子对象,比如Text对象,它并不存在子节点,这一点是要注意的。Node对象所包含的主要的方法有:
1. getNextSibling():返回在DOM树中这个节点的下一个兄弟节点。
2. getPreviousSibling()方法返回其前一个兄弟节点。
3. getNodeName():根据节点的类型返回节点的名称。
4. getNodeType():返回节点的类型。
5. getNodeValue():返回节点的值。
6. hasChildNodes():判断是不是存在有子节点。
7. hasAttributes():判断这个节点是否存在有属性。
8. getOwnerDocument():返回节点所处的Document对象。
9. insertBefore(org.w3c.dom.Node new,org.w3c.dom.Node ref):在给定的一个子对象前再插入一个子对象。
10. removeChild(org.w3c.dom.Node):删除给定的子节点对象。
11. replaceChild(org.w3c.dom.Node new,org.w3c.dom.Node old):用一个新的Node对象代替给定的子节点对象。
12. appendChild(org.w3c.dom.Node):为这个节点添加一个子节点,并放在所有子节点的最后,如果这个子节点已经存在,则先把它删掉再添加进去。
13. getFirstChild():如果节点存在子节点,则返回第一个子节点。
14. getLastChild()方法返回最后一个子节点。
3. NodeList对象
NodeList对象,顾名思义,就是代表了一个包含了一个或者多个Node的列表。可以简单的把它看成一个Node的数组,我们可以通过方法来获得列表中的元素:
1. GetLength():返回列表的长度。
2. Item(int):返回指定位置的Node对象。
4. Element对象
Element对象代表的是XML文档中的标签元素,继承于Node,亦是Node的最主要的子对象。在标签中可以包含有属性,因而Element对象中有存取其属性的方法,而任何Node中定义的方法,也可以用在Element对象上面。Element对象所包含的主要的方法有:
1. getElementsByTagName(String):返回一个NodeList对象,它包含了在这个标签中其下的子孙节点中具有给定标签名字的标签。
2. getTagName():返回一个代表这个标签名字的字符串。
3. getAttribute(String):返回标签中给定属性名称的属性的值。在这儿需要主要的是,应为XML文档中允许有实体属性出现,而这个方法对这些实体属性并不适用。
4. getAttributeNodes()方法来得到一个Attr对象来进行进一步的操作。
5. getAttributeNode(String):返回一个代表给定属性名称的Attr对象。
5. Attr对象
Attr对象代表了某个标签中的属性。Attr继承于Node,但是因为Attr实际上是包含在Element中的,它并不能被看作是Element的子对象,因而在DOM中Attr并不是DOM树的一部分,所以Node中的getparentNode(),getpreviousSibling()和getnextSibling()返回的都将是null。也就是说,Attr其实是被看作包含它的Element对象的一部分,它并不作为DOM树中单独的一个节点出现。
Dom解析XML
解析步骤
1. 获取DocumentBuilderFactory
2. 通过DocumentBuilder工厂产生一个DocumentBuilder
3. 利用DocumentBuilder产生Document
Document可以看成是xml文件在内存中的一个镜像,这样,我们可以通过操作Document来实现对xml文件的操作。
例子
1. 测试用xml
<?xml version="1.0" encoding="UTF-8"?> <struts> <constant name="struts.i18n.encoding" value="gb2312">324</constant> <package name="stuts2" extends="struts-default"> <action name="login" class="ActionUnit.Person"> <result name="s">1_1.jsp</result> <result name="t">1_2.jsp</result> <result name="m">1_3.jsp</result> <result name="fail">1_4.jsp</result> </action> <action name="modifyPassword" class="student.ModifyPassword"> <result name="success">2_1.jsp</result> <result name="fail">2_2.jsp</result> </action> <action name="studentquery" class="student.QueryScore"> <result name="success">3_1.jsp</result> <result name="false">3_2.jsp</result> </action> <action name="infoquery" class="student.QueryInfo"> <result name="success">4_1.jsp</result> <result name="false">4_2.jsp</result> </action> </package> </struts>
2. 代码
public class XMLReader {
public static void main(String[] args) {
try {
File f = new File("MyXml.xml");
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();//步骤1
DocumentBuilder builder = factory.newDocumentBuilder();//步骤2
Document doc = builder.parse(f);//步骤3
NodeList nl = doc.getElementsByTagName("action");
for (int i = 0; i < nl.getLength(); i++) {
System.out.println("result:"+ doc.getElementsByTagName("result")
.item(i).getFirstChild().getNodeValue());
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
3. 运行结果
result:1_1.jsp result:1_2.jsp result:1_3.jsp result:1_4.jsp
步骤3有一个方法parse(File f),用来将给定文件的内容解析为一个XML文档,并返回一个新的Document对象。获取到Document对象后,再获取节点的值应该不是问题了。
Dom解析XML所有节点例子
1. xml测试文档
<?xml version = "1.0" encoding = "utf-8"?> <School> <Student> <Name>沈浪</Name> <Num>1006010022</Num> <Classes>信管2</Classes> <Address>浙江杭州3</Address> <Tel>123456</Tel> </Student> <Student> <Name>沈1</Name> <Num>1006010033</Num> <Classes>信管1</Classes> <Address>浙江杭州4</Address> <Tel>234567</Tel> </Student> <Student> <Name>沈2</Name> <Num>1006010044</Num> <Classes>生工2</Classes> <Address>浙江杭州1</Address> <Tel>345678</Tel> </Student> <Student> <Name>沈3</Name> <Num>1006010055</Num> <Classes>电子2</Classes> <Address>浙江杭州2</Address> <Tel>456789</Tel> </Student> </School>
2. 代码
/**
* 遍历解析xml文档
* */
public static void queryXml() {
try {
//得到DOM解析器的工厂实例
DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance();
//从DOM工厂中获得DOM解析器
DocumentBuilder dbBuilder = dbFactory.newDocumentBuilder();
//把要解析的xml文档读入DOM解析器
Document doc = dbBuilder.parse("src/xidian/sl/dom/school.xml");
System.out.println("处理该文档的DomImplementation对象 = " + doc.getImplementation());
//得到文档名称为Student的元素的节点列表
NodeList nList = doc.getElementsByTagName("Student");
//遍历该集合,显示结合中的元素及其子元素的名字
for (int i = 0; i < nList.getLength(); i++) {
Element node = (Element) nList.item(i);
System.out.println("Name: " + node.getElementsByTagName("Name").item(0).getFirstChild().getNodeValue());
System.out.println("Num: " + node.getElementsByTagName("Num").item(0).getFirstChild().getNodeValue());
System.out.println("Classes: " + node.getElementsByTagName("Classes").item(0).getFirstChild().getNodeValue());
System.out.println("Address: " + node.getElementsByTagName("Address").item(0).getFirstChild().getNodeValue());
System.out.println("Tel: " + node.getElementsByTagName("Tel").item(0).getFirstChild().getNodeValue());
}
} catch(Exception e) {
// TODO: handle exception
e.printStackTrace();
}
}
运行结果
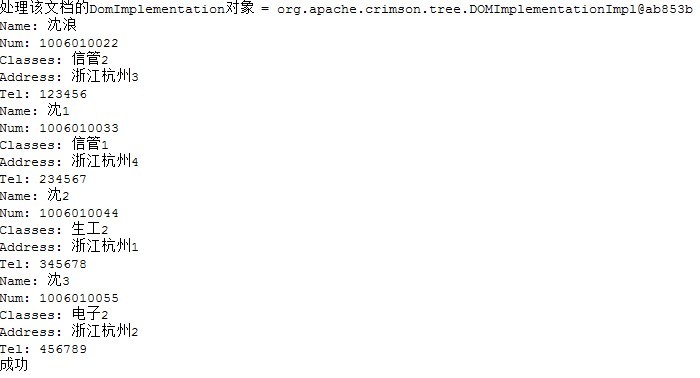
总结
1. DOM接口提供了一种通过分层对象模型来访问XML文档信息的方式,这些分层对象模型依据XML的文档结构形成了一棵节点树。无论XML文档中所描述的是什么类型的信息,即便是制表数据、项目列表或一个文档,利用DOM所生成的模型都是节点树的形式。也就是说,DOM强制使用树模型来访问XML文档中的信息。由于XML本质上就是一种分层结构,所以这种描述方法是相当有效的。
2. DOM树所提供的随机访问方式给应用程序的开发带来了很大的灵活性,它可以任意地控制整个XML文档中的内容。然而,由于DOM解析器把整个XML文档转化成DOM树放在了内存中,因此,当文档比较大或者结构比较复杂时,对内存的需求就比较高。而且,对于结构复杂的树的遍历也是一项耗时的操作。所以,DOM解析器对机器性能的要求比较高,实现效率不十分理想。不过,由于DOM解析器所采用的树结构的思想与XML文档的结构相吻合,同时鉴于随机访问所带来的方便,因此,DOM解析器还是有很广泛的使用价值的。
3. DOM 最大的特点是:实现 W3C 标准,有多种编程语言支持这种解析方式,并且这种方法本身操作上简单快捷,十分易于初学者掌握。其处理方式是将 XML 整个作为类似树结构的方式读入内存中以便操作及解析,因此支持应用程序对 XML 数据的内容和结构进行修改,但是同时由于其需要在处理开始时将整个 XML 文件读入到内存中去进行分析,因此其在解析大数据量的 XML 文件时会遇到类似于内存泄露以及程序崩溃的风险,请对这点多加注意。
版权声明:本文为JAVASCHOOL原创文章,未经本站允许不得转载。