
Java XML解析 - 利用SAX(Simple API for XML)解析XML
SAX不用将整个文档加载到内存,基于事件驱动的API(Observer模式),他按照xml文件的顺序一步一步的来解析,用户只需要注册自己感兴趣的事件即可。SAX提供EntityResolver, DTDHandler, ContentHandler, ErrorHandler接口,分别用于监听解析实体事件、DTD处理事件、正文处理事件和处理出错事件,与AWT类似,SAX还提供了一个对这4个接口默认的类DefaultHandler(这里的默认实现,其实就是一个空方法),一般只要继承DefaultHandler,重写自己感兴趣的事件即可。
原理
Sax采用事件驱动的方式解析文档。简单点说,如同在电影院看电影一样,从头到尾看一遍就完了,不能回退(Dom可来来回回读取),例如在看电影的过程中,每遇到一个情节,一段泪水,一次擦肩,你都会调动大脑和神经去接收或处理这些信息。同样,在Sax的解析过程中,读取到文档开头、结尾,元素的开头和结尾都会触发一些回调方法,你可以在这些回调方法中进行相应事件处理,这四个方法是:startDocument() 、 endDocument()、 startElement()、 endElement。此外,光读取到节点处是不够的,我们还需要characters()方法来仔细处理元素内包含的内容,将这些回调方法集合起来,便形成了一个类,这个类也就是我们需要的触发器。
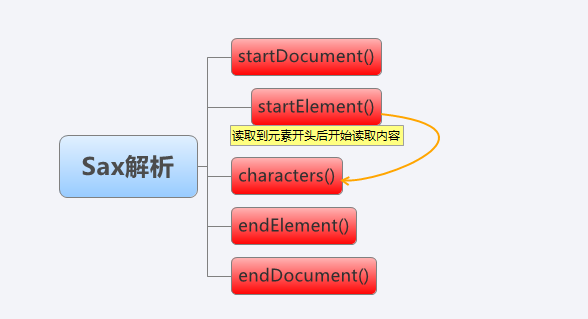
如上图,在触发器中,首先开始读取文档,然后开始逐个解析元素,每个元素中的内容会返回到characters()方法,接着结束元素读取,所有元素读取完后,结束文档解析。
SAX XML解析步骤
1. Java Sax在解析xml文件之前,我们要先了解xml文件的节点的种类,一种是ElementNode,一种是TextNode。如下面的这段book.xml
<?xml version="1.0" encoding="UTF-8"?> <books> <book id="12"> <name>thinking in java</name> <price>85.5</price> </book> <book id="15"> <name>Spring in Action</name> <price>39.0</price> </book> </books>
其中,像<books>、<book>这种节点就属于ElementNode,而thinking in Java、85.5这种就属于TextNode。下面结合一张图来详细讲解Sax解析。

2. 将xml载入SAX,然后解析。见下面代码:
//SaxParseService.java
public class SaxParseService extends DefaultHandler{
private List<Book> books = null;
private Book book = null;
private String preTag = null;//作用是记录解析时的上一个节点名称
public List<Book> getBooks(InputStream xmlStream) throws Exception{
SAXParserFactory factory = SAXParserFactory.newInstance();
SAXParser parser = factory.newSAXParser();
SaxParseService handler = new SaxParseService();
parser.parse(xmlStream, handler);
return handler.getBooks();
}
public List<Book> getBooks(){
return books;
}
@Override
public void startDocument() throws SAXException {
books = new ArrayList<Book>();
}
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
if("book".equals(qName)){
book = new Book();
book.setId(Integer.parseInt(attributes.getValue(0)));
}
preTag = qName;//将正在解析的节点名称赋给preTag
}
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
if("book".equals(qName)){
books.add(book);
book = null;
}
preTag = null;/**当解析结束时置为空。这里很重要,例如,当图中画3的位置结束后,会调用这个方法
,如果这里不把preTag置为null,根据startElement(....)方法,preTag的值还是book,当文档顺序读到图
中标记4的位置时,会执行characters(char[] ch, int start, int length)这个方法,而characters(....)方
法判断preTag!=null,会执行if判断的代码,这样就会把空值赋值给book,这不是我们想要的。*/
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
if(preTag!=null){
String content = new String(ch,start,length);
if("name".equals(preTag)){
book.setName(content);
}else if("price".equals(preTag)){
book.setPrice(Float.parseFloat(content));
}
}
}
}
//Book.java 主要是用来组装数据
public class Book {
private int id;
private String name;
private float price;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public float getPrice() {
return price;
}
public void setPrice(float price) {
this.price = price;
}
@Override
public String toString(){
return this.id+":"+this.name+":"+this.price;
}
}
//ParseTest
public class ParseTest extends TestCase{
public void testSAX() throws Throwable{
SaxParseService sax = new SaxParseService();
InputStream input = this.getClass().getClassLoader().getResourceAsStream("book.xml");
List<Book> books = sax.getBooks(input);
for(Book book : books){
System.out.println(book.toString());
}
}
}
xml文件被Sax解析器载入,由于Sax解析是按照xml文件的顺序来解析,当读入<?xml.....>时,会调用startDocument()方法,当读入<books>的时候,由于它是个ElementNode,所以会调用startElement(String uri, String localName, String qName, Attributes attributes) 方法,其中第二个参数就是节点的名称,注意:由于有些环境不一样,有时候第二个参数有可能为空,所以可以使用第三个参数,因此在解析前,先调用一下看哪个参数能用,第4个参数是这个节点的属性。这里我们不需要这个节点,所以从<book>这个节点开始,也就是图中1的位置,当读入时,调用startElement(....)方法,由于只有一个属性id,可以通过attributes.getValue(0)来得到,然后在图中标明2的地方会调用characters(char[] ch, int start, int length)方法,不要以为那里是空白,Sax解析器可不那么认为,Sax解析器会把它认为是一个TextNode。但是这个空白不是我们想要的数据,我们是想要<name>节点下的文本信息。这就要定义一个记录当上一节点的名称的TAG,在characters(.....)方法中,判断当前节点是不是name,是再取值,才能取到thinking in java。
SAX解析xml详细例子
//要解析的XML文件:myClass.xml <?xml version="1.0" encoding="utf-8"?> <class> <stu id="001"> <name>Allen</name> <sex>男</sex> <age>20</age> </stu> <stu id="002"> <name>namy</name> <sex>女</sex> <age>18</age> </stu> <stu id="003"> <name>lufy</name> <sex>男</sex> <age>18</age> </stu> </class>
/**
* 用SAX解析XML的Handler
*/
public class Myhandler extends DefaultHandler {
//存储正在解析的元素的数据
private Map<String,String> map=null;
//存储所有解析的元素的数据
private List<Map<String,String>> list=null;
//正在解析的元素的名字
String currentTag=null;
//正在解析的元素的元素值
String currentValue=null;
//开始解析的元素
String nodeName=null;
public Myhandler(String nodeName) {
// TODO Auto-generated constructor stub
this.nodeName=nodeName;
}
public List<Map<String, String>> getList() {
return list;
}
//开始解析文档,即开始解析XML根元素时调用该方法
@Override
public void startDocument() throws SAXException {
// TODO Auto-generated method stub
System.out.println("--startDocument()--");
//初始化Map
list=new ArrayList<Map<String,String>>();
}
//开始解析每个元素时都会调用该方法
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
// TODO Auto-generated method stub
//判断正在解析的元素是不是开始解析的元素
System.out.println("--startElement()--"+qName);
if(qName.equals(nodeName)){
map=new HashMap<String, String>();
}
//判断正在解析的元素是否有属性值,如果有则将其全部取出并保存到map对象中,如:<person id="00001"></person>
if(attributes!=null&&map!=null){
for(int i=0;i<attributes.getLength();i++){
map.put(attributes.getQName(i), attributes.getValue(i));
}
}
currentTag=qName; //正在解析的元素
}
//解析到每个元素的内容时会调用此方法
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
// TODO Auto-generated method stub
System.out.println("--characters()--");
if(currentTag!=null&&map!=null){
currentValue=new String(ch,start,length);
//如果内容不为空和空格,也不是换行符则将该元素名和值和存入map中
if(currentValue!=null&&!currentValue.trim().equals("")&&!currentValue.trim().equals("\n")){
map.put(currentTag, currentValue);
System.out.println("-----"+currentTag+" "+currentValue);
}
//当前的元素已解析过,将其置空用于下一个元素的解析
currentTag=null;
currentValue=null;
}
}
//每个元素结束的时候都会调用该方法
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
// TODO Auto-generated method stub
System.out.println("--endElement()--"+qName);
//判断是否为一个节点结束的元素标签
if(qName.equals(nodeName)){
list.add(map);
map=null;
}
}
//结束解析文档,即解析根元素结束标签时调用该方法
@Override
public void endDocument() throws SAXException {
// TODO Auto-generated method stub
System.out.println("--endDocument()--");
super.endDocument();
}
}
/**
* 用于解析XML的业务类:SaxService.java
*/
public class SaxService {
public static List<Map<String,String>> ReadXML(String uri,String NodeName){
try {
//创建一个解析XML的工厂对象
SAXParserFactory parserFactory=SAXParserFactory.newInstance();
//创建一个解析XML的对象
SAXParser parser=parserFactory.newSAXParser();
//创建一个解析助手类
Myhandler myhandler=new Myhandler("stu");
parser.parse(uri, myhandler);
return myhandler.getList();
} catch (Exception e) {
e.printStackTrace();
}finally{
}
return null;
}
}
/**
* 程序入口
*/
public class XmlSaxTest {
public static void main(String[] args) {
// TODO Auto-generated method stub
ArrayList<Map<String, String>> list=(ArrayList<Map<String, String>>) SaxService.ReadXML("M:\\XML\\Demo\\myClass.xml","class");
/*for(int i=0;i<list.size();i++){
HashMap<String, String> temp=(HashMap<String, String>) list.get(i);
Iterator<String> iterator=temp.keySet().iterator();
while(iterator.hasNext()){
String key=iterator.next().toString();
String value=temp.get(key);
System.out.print(key+" "+value+"--");
}
}*/
System.out.println(list.toString());
}
}
执行结果:
--startDocument()--
--startElement()--class
--characters()--
--startElement()--stu
--characters()--
--startElement()--name
--characters()--
-----name Allen
--endElement()--name
--characters()--
--startElement()--sex
--characters()--
-----sex 男
--endElement()--sex
--characters()--
--startElement()--age
--characters()--
-----age 20
--endElement()--age
--characters()--
--endElement()--stu
--characters()--
--startElement()--stu
--characters()--
--startElement()--name
--characters()--
-----name namy
--endElement()--name
--characters()--
--startElement()--sex
--characters()--
-----sex 女
--endElement()--sex
--characters()--
--startElement()--age
--characters()--
-----age 18
--endElement()--age
--characters()--
--endElement()--stu
--characters()--
--startElement()--stu
--characters()--
--startElement()--name
--characters()--
-----name lufy
--endElement()--name
--characters()--
--startElement()--sex
--characters()--
-----sex 男
--endElement()--sex
--characters()--
--startElement()--age
--characters()--
-----age 18
--endElement()--age
--characters()--
--endElement()--stu
--characters()--
--endElement()--class
--endDocument()--
[{id=001, sex=男, age=20, name=Allen}, {id=002, sex=女, age=18, name=namy}, {id=003, sex=男, age=18, name=lufy}]
总结
用SAX解析XML采用的是从上而下的基于事件驱动的解析方式,在解析过程中会视情况自动调用startDocument()、startElement()、characters()、endElement()、endDocument()等相关的方法。
1. startDocument()方法只会在文档开始解析的时候被调用,每次解析只会调用一次。
2. startElement()方法每次在开始解析一个元素,即遇到元素标签开始的时候都会调用。
3. characters()方法也是在每次解析到元素标签携带的内容时都会调用,即使该元素标签的内容为空或换行。而且如果元素内嵌套元素,在父元素结束标签前, characters()方法会再次被调用,此处需要注意。
4. endElement()方法每次在结束解析一个元素,即遇到元素标签结束的时候都会调用。
5. endDocument() startDocument()方法只会在文档解析结束的时候被调用,每次解析只会调用一次。
版权声明:本文为JAVASCHOOL原创文章,未经本站允许不得转载。