
ElasticSearch(es)原理
ElasticSearch是一个分布式文档数据库,其中每个字段均可被索引,而且每个字段的数据均可被搜索,能够横向扩展至数以百计的服务器存储以及处理PB级的数据。
基本概念
索引(Index)
ElasticSearch将数据存储于一个或多个索引中,索引是具有类似特性的文档的集合。类比传统的关系型数据库领域来说,索引相当于SQL中的一个数据库,或者一个数据存储方案(schema)。索引由其名称(必须为全小写字符)进行标识,并通过引用此名称完成文档的创建、搜索、更新及删除操作。一个ES集群中可以按需创建任意数目的索引。
类型(Type)
类型是索引内部的逻辑分区(category/partition),然而其意义完全取决于用户需求。因此,一个索引内部可定义一个或多个类型(type)。一般来说,类型就是为那些拥有相同的域的文档做的预定义。例如,在索引中,可以定义一个用于存储用户数据的类型,一个存储日志数据的类型,以及一个存储评论数据的类型。类比传统的关系型数据库领域来说,类型相当于“表”。
文档(Document)
文档是索引和搜索的原子单位,它是包含了一个或多个域(Field)的容器,基于JSON格式进行表示。文档由一个或多个域组成,每个域拥有一个名字及一个或多个值,有多个值的域通常称为“多值域”。每个文档可以存储不同的域集,但同一类型下的文档至应该有某种程度上的相似之处。
倒排索引(Inverted Index)
每一个文档都对应一个ID。倒排索引会按照指定语法对每一个文档进行分词,然后维护一张表,列举所有文档中出现的terms以及它们出现的文档ID和出现频率。搜索时同样会对关键词进行同样的分词分析,然后查表得到结果。
节点(Node)
一个运行中的 Elasticsearch 实例称为一个节点,而集群是由一个或者多个拥有相同cluster.name配置的节点组成, 它们共同承担数据和负载的压力。
分片(Shard)
一个索引中的数据保存在多个分片中,相当于水平分表。一个分片便是一个Lucene 的实例,它本身就是一个完整的搜索引擎。我们的文档被存储和索引到分片内,但是应用程序是直接与索引而不是与分片进行交互。
ElasticSearch实际上就是利用分片来实现分布式。分片是数据的容器,文档保存在分片内,分片又被分配到集群内的各个节点里。 当你的集群规模扩大或者缩小时, ES会自动的在各节点中迁移分片,使得数据仍然均匀分布在集群里。
索引原理
(1)传统的关系型数据库
二叉树查找效率是logN,同时插入新的节点不必移动全部节点,所以用树型结构存储索引,能同时兼顾插入和查询的性能。因此在这个基础上,再结合磁盘的读取特性(顺序读/随机读),传统关系型数据库采用了B-Tree/B+Tree这样的数据结构做索引
(2)ES
采用倒排索引
那么,倒排索引是个什么样子呢?

首先,来搞清楚几个概念,为此,举个例子:
假设有个user索引,它有四个字段:分别是name,gender,age,address。画出来的话,大概是下面这个样子,跟关系型数据库一样

Term(单词):一段文本经过分析器分析以后就会输出一串单词,这一个一个的就叫做Term
Term Dictionary(单词字典):顾名思义,它里面维护的是Term,可以理解为Term的集合
Term Index(单词索引):为了更快的找到某个单词,我们为单词建立索引
Posting List(倒排列表):倒排列表记录了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息,每条记录称为一个倒排项(Posting)。根据倒排列表,即可获知哪些文档包含某个单词。(PS:实际的倒排列表中并不只是存了文档ID这么简单,还有一些其它的信息,比如:词频(Term出现的次数)、偏移量(offset)等,可以想象成是Python中的元组,或者Java中的对象)
(PS:如果类比现代汉语词典的话,那么Term就相当于词语,Term Dictionary相当于汉语词典本身,Term Index相当于词典的目录索引)
实时架构原理
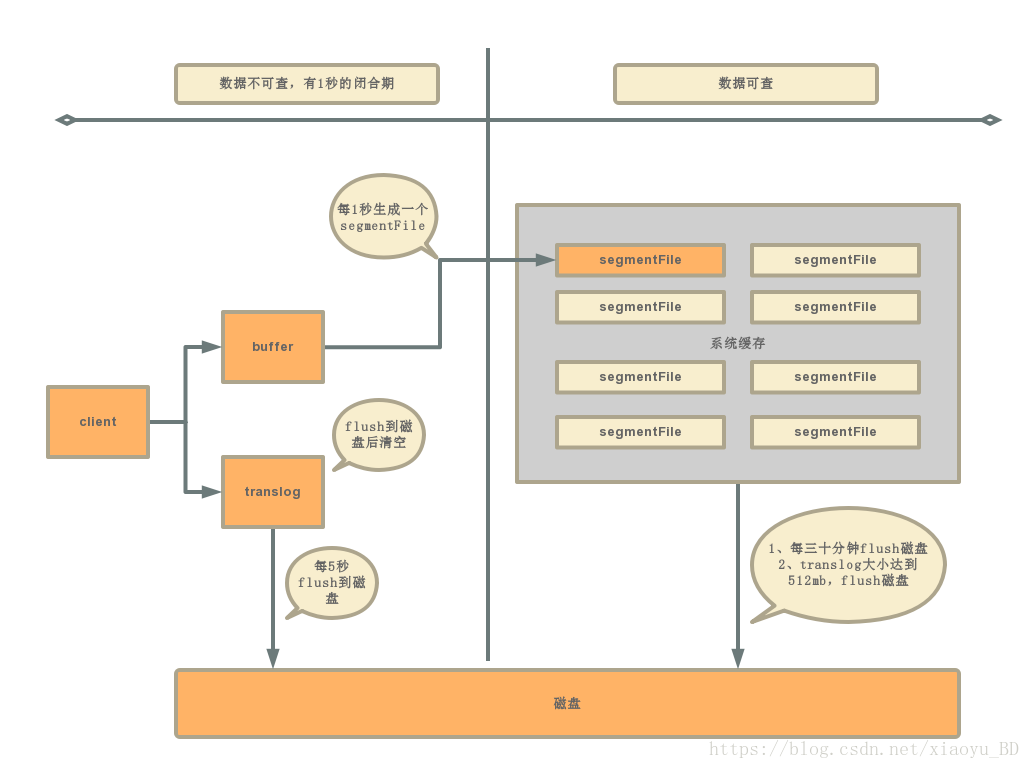
首先,当我们对记录进行修改时,es会把数据同时写到内存缓存区和translog中。而这个时候数据是不能被搜索到的,只有数据形成了segmentFile,才会被搜索到。默认情况下,es每隔一秒钟执行一次refresh,可以通过参数index.refresh_interval来修改这个刷新间隔,执行refresh主要做三件事:
1、所有在内存缓冲区中的文档被写入到一个新的segment中,但是没有调用fsync,因此内存中的数据可能丢失
2、segment被打开使得里面的文档能够被搜索到
3、清空内存缓冲区
从上面可以看出,内存缓存中的数据,每一秒会生成一个新的segment,一分钟就会生成60个segments。只有在生成segment之后,才会被索引到,所以这里说并非realtime,而是near-realtime。
translog的相当于事务日志,记录着所有对Elasticsearch的操作记录,也是对Elasticsearch的一种备份。因为并不是写到segment就表示数据落到磁盘了,实际上segment是存储在系统缓存(page cache)中的,只有达到一个周期或者数据量达到一定值,才会flush到磁盘上。这个时候如果系统内存中的segment丢失,是可以通过translog来恢复的。这个flush过程主要做了三件事:
1、往磁盘里写入commit point信息。
2、文件系统中的segment,fsync到磁盘。
3、清空translog文件。
translog可以保证缓存中的segment的恢复,但translog也不是实时也磁盘的,也就是说,内存中的translog丢了的话,也会有丢失数据的可能。所以translog也要进行flush。translog的flush主要有三个条件:
1、可以设置是否在某些操作之后进行强制flush,比如索引的删除或批量请求之后。
2、translog大小超过512mb或者超过三十分钟会强制对segment进行flush,随后会强制对translog进行flush,这种情况缓存中的translog在flush之后会被清空。
3、默认5s,会强制对translog进行flush。最小值可配置100ms。
数据操作
ElasticSearch查询原理,查询的过程大体上分为查询(query)和取回(fetch)两个阶段
动态更新索引
Lucene 把每次生成的倒排索引,叫做一个段(segment)。然后另外使用一个 commit 文件,记录索引内所有的 segment。而生成 segment 的数据来源,则是内存中的 buffer。也就是说,动态更新过程如下:
当前索引有 3 个 segment 可用。索引状态如图 2-1;
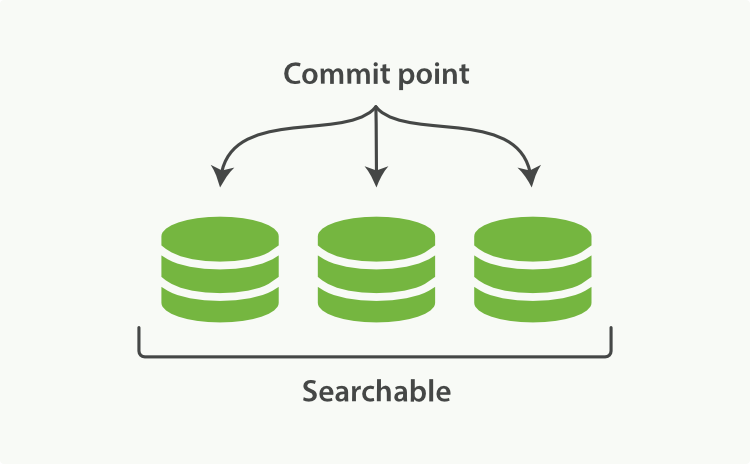
图 2-1
新接收的数据进入内存 buffer。索引状态如图 2-2;
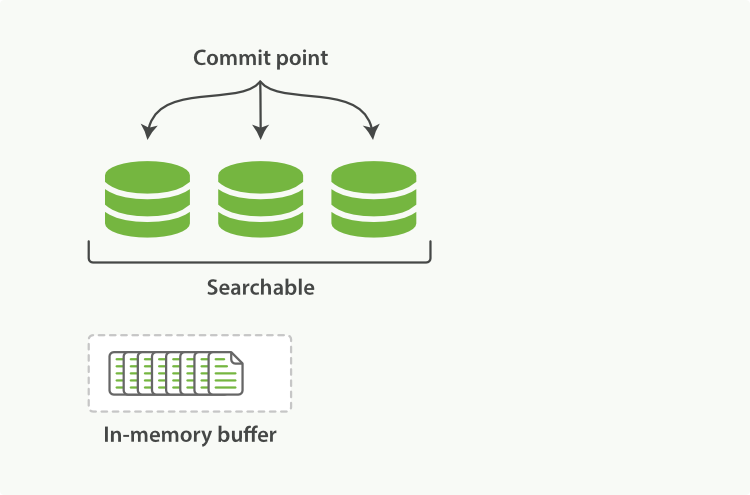
图 2-2
内存 buffer 刷到磁盘,生成一个新的 segment,commit 文件同步更新。索引状态如图 2-3。
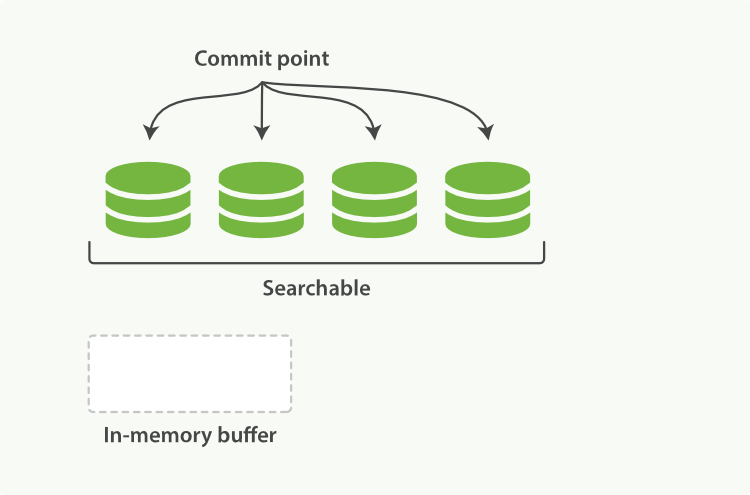
图 2-3
磁盘缓存实现准实时检索
磁盘太慢了!对我们要求实时性很高的服务来说,这种处理还不够
内存 buffer 生成一个新的 segment,刷到文件系统缓存中,Lucene 即可检索这个新 segment。索引状态如图 2-4
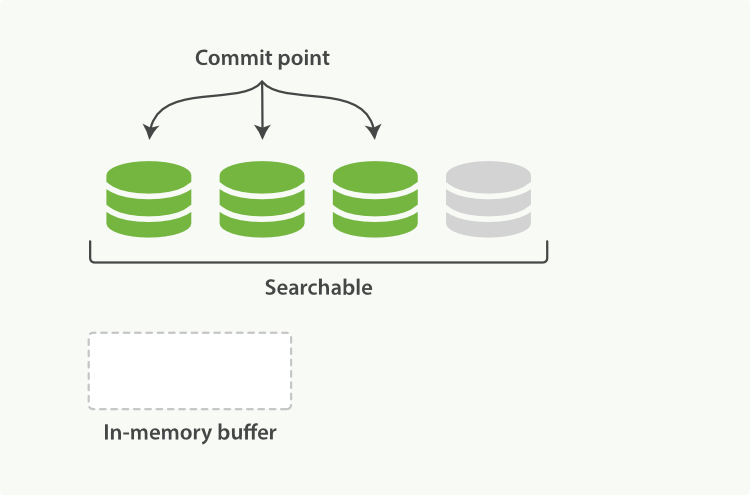
文件系统缓存真正同步到磁盘上,commit 文件更新。达到图 2-3 中的状态。这一步刷到文件系统缓存的步骤,在 Elasticsearch 中,是默认设置为 1 秒间隔的,对于大多数应用来说,几乎就相当于是实时可搜索了。
ElasticSearch很强大,一般用于以下几种场景
全文检索
es的主要应用场景之一,类似于Google搜索,百度搜索和维基百科等,对全文关键字进行检索。
日志分析
海量数据进行近实时的处理,对复杂的日志进行分析,得到我们想要的结果。
复杂条件查询
数据量很大,又需要各种条件查询,实时的返回查询数据结果,如管理后台
相似搜索,模糊匹配,地理位置聚合等
版权声明:本文为JAVASCHOOL原创文章,未经本站允许不得转载。