
ElasticSearch(es)查询读操作(Read)
ElasticSearch查询的过程大体上分为查询(query)和取回(fetch)两个阶段。这个节点的任务是广播查询请求到所有相关分片,并将它们的响应整合成全局排序后的结果集合,这个结果集合会返回给客户端。
查询阶段
当一个节点接收到一个搜索请求,则这个节点就变成了协调节点。
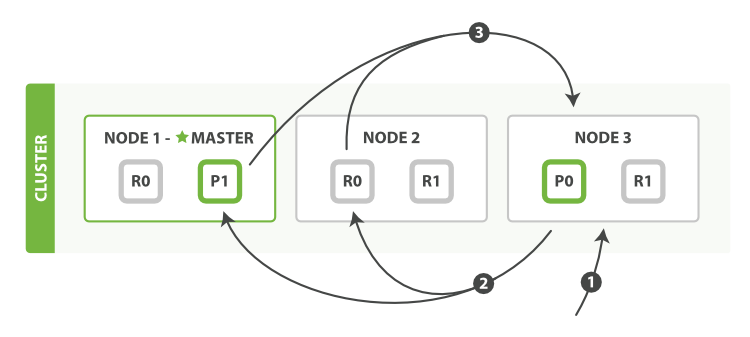
图1、查询过程分布式搜索
第一步是广播请求到索引中每一个节点的分片拷贝。 查询请求可以被某个主分片或某个副本分片处理,协调节点将在之后的请求中轮询所有的分片拷贝来分摊负载。
每个分片将会在本地构建一个优先级队列。如果客户端要求返回结果排序中从第from名开始的数量为size的结果集,则每个节点都需要生成一个from+size大小的结果集,因此优先级队列的大小也是from+size。分片仅会返回一个轻量级的结果给协调节点,包含结果集中的每一个文档的ID和进行排序所需要的信息。
协调节点会将所有分片的结果汇总,并进行全局排序,得到最终的查询排序结果。此时查询阶段结束。
取回阶段
查询过程得到的是一个排序结果,标记出哪些文档是符合搜索要求的,此时仍然需要获取这些文档返回客户端。
协调节点会确定实际需要返回的文档,并向含有该文档的分片发送get请求;分片获取文档返回给协调节点;协调节点将结果返回给客户端。
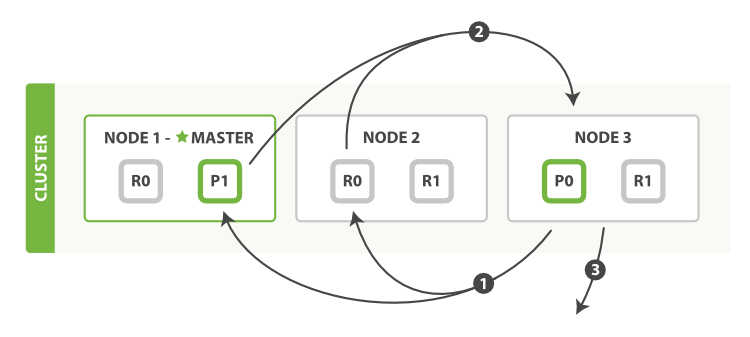
图2、分布式搜索的取回阶段
es相关性计算
在搜索过程中对文档进行排序,需要对每一个文档进行打分,判别文档与搜索条件的相关程度。在旧版本的ES中默认采用TF/IDF(term frequency/inverse document frequency)算法对文档进行打分。
版权声明:本文为JAVASCHOOL原创文章,未经本站允许不得转载。