
Java Map类
Map 提供了一个更通用的元素存储方法。Map 集合类用于存储元素对(称作“键”和“值”),其中每个键映射到一个值。从概念上而言,您可以将 List 看作是具有数值键的 Map。
构造函数定义
public interface Map<K,V> { }
方法
abstract void clear()
abstract boolean containsKey(Object key)
abstract boolean containsValue(Object value)
abstract Set<Entry<K, V>> entrySet()
abstract boolean equals(Object object)
abstract V get(Object key)
abstract int hashCode()
abstract boolean isEmpty()
abstract Set<K> keySet()
abstract V put(K key, V value)
abstract void putAll(Map<? extends K, ? extends V> map)
abstract V remove(Object key)
abstract int size()
abstract Collection<V> values()
1. Map提供接口分别用于返回 键集、值集或键-值映射关系集。entrySet()用于返回键-值集的Set集合;keySet()用于返回键集的Set集合;values()用户返回值集的Collection集合,因为Map中不能包含重复的键;每个键最多只能映射到一个值。所以,键-值集、键集都是Set,值集时Collection。
2. Map提供了“键-值对”、“根据键获取值”、“删除键”、“获取容量大小”等方法。
架构
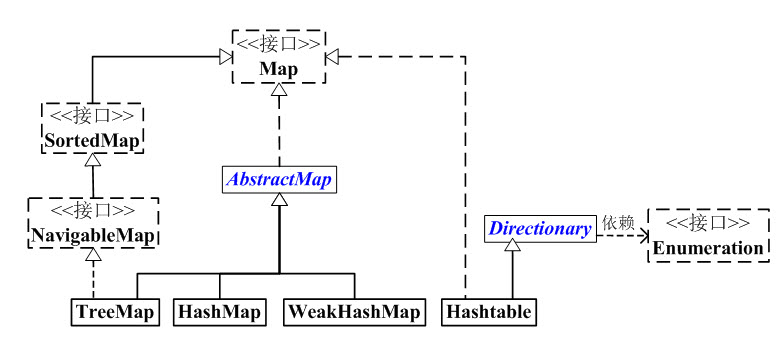
如上图:
(01) Map 是映射接口,Map中存储的内容是键值对(key-value)。
(02) AbstractMap 是继承于Map的抽象类,它实现了Map中的大部分API。其它Map的实现类可以通过继承AbstractMap来减少重复编码。
(03) SortedMap 是继承于Map的接口。SortedMap中的内容是排序的键值对,排序的方法是通过比较器(Comparator)。
(04) NavigableMap 是继承于SortedMap的接口。相比于SortedMap,NavigableMap有一系列的导航方法;如"获取大于/等于某对象的键值对"、“获取小于/等于某对象的键值对”等等。
(05) TreeMap 继承于AbstractMap,且实现了NavigableMap接口;因此,TreeMap中的内容是“有序的键值对”!
(06) HashMap 继承于AbstractMap,但没实现NavigableMap接口;因此,HashMap的内容是“键值对,但不保证次序”!
(07) Hashtable 虽然不是继承于AbstractMap,但它继承于Dictionary(Dictionary也是键值对的接口),而且也实现Map接口;因此,Hashtable的内容也是“键值对,也不保证次序”。但和HashMap相比,Hashtable是线程安全的,而且它支持通过Enumeration去遍历。
(08) WeakHashMap 继承于AbstractMap。它和HashMap的键类型不同,WeakHashMap的键是“弱键”。
优化
调整 Map 实现的大小
在哈希术语中,内部数组中的每个位置称作“存储桶”(bucket),而可用的存储桶数(即内部数组的大小)称作容量 (capacity)。为使 Map 对象有效地处理任意数目的项,Map 实现可以调整自身的大小。但调整大小的开销很大。调整大小需要将所有元素重新插入到新数组中,这是因为不同的数组大小意味着对象现在映射到不同的索引值。先前冲突的键可能不再冲突,而先前不冲突的其他键现在可能冲突。这显然表明,如果将 Map 调整得足够大,则可以减少甚至不再需要重新调整大小,这很有可能显著提高速度。
使用负载因子
为了确认何时需要调整Map容器,Map使用了一个额外的参数并且粗略计算存储容器的密度。在Map调整大小之前,使用”负载因子”来指示Map将会承担的“负载量”,也就是它的负载程度,当容器中元素的数量达到了这个“负载量”,则Map将会进行扩容操作。负载因子、容量、Map大小之间的关系如下:负载因子 * 容量 > map大小 ----->调整Map大小。
例如:如果负载因子大小为0.75(HashMap的默认值),默认容量为11,则 11 * 0.75 = 8.25 = 8,所以当我们容器中插入第八个元素的时候,Map就会调整大小。
负载因子本身就是在控件和时间之间的折衷。当我使用较小的负载因子时,虽然降低了冲突的可能性,使得单个链表的长度减小了,加快了访问和更新的速度,但是它占用了更多的控件,使得数组中的大部分控件没有得到利用,元素分布比较稀疏,同时由于Map频繁的调整大小,可能会降低性能。但是如果负载因子过大,会使得元素分布比较紧凑,导致产生冲突的可能性加大,从而访问、更新速度较慢。所以我们一般推荐不更改负载因子的值,采用默认值0.75.
Map哈希映射技术
几乎所有通用Map都使用哈希映射技术。对于我们程序员来说我们必须要对其有所了解。
哈希映射技术是一种就元素映射到数组的非常简单的技术。由于哈希映射采用的是数组结果,那么必然存在一中用于确定任意键访问数组的索引机制,该机制能够提供一个小于数组大小的整数,我们将该机制称之为哈希函数。在Java中我们不必为寻找这样的整数而大伤脑筋,因为每个对象都必定存在一个返回整数值的hashCode方法,而我们需要做的就是将其转换为整数,然后再将该值除以数组大小取余即可。如下:
int hashValue = Maths.abs(obj.hashCode()) % size;
下图是哈希映射的基本原理图:

在该图中1-4步骤是找到该元素在数组中位置,5-8步骤是将该元素插入数组中。在插入的过程中会遇到一点点小挫折。在众多肯能存在多个元素他们的hash值是一样的,这样就会得到相同的索引位置,也就说多个元素会映射到相同的位置,这个过程我们称之为“冲突”。解决冲突的办法就是在索引位置处插入一个链接列表,并简单地将元素添加到此链接列表。当然也不是简单的插入,在HashMap中的处理过程如下:获取索引位置的链表,如果该链表为null,则将该元素直接插入,否则通过比较是否存在与该key相同的key,若存在则覆盖原来key的value并返回旧值,否则将该元素保存在链头(最先保存的元素放在链尾)。
例子
public class MapDemo
{
public static void main(String[] args)
{
Map<String,Integer> m = new HashMap<String,Integer>();
m.put("zhangsan", 19);
m.put("lisi", 49);
m.put("wangwu", 19);
m.put("lisi",20);
m.put("hanmeimei", null);
System.out.println(m);
System.out.println(m.remove("wangwu"));
m.clear();
System.out.println(m);
}
}
总结
1. Map 是一个键值对(key-value)映射接口。Map映射中不能包含重复的键;每个键最多只能映射到一个值。
2. Map 接口提供三种collection 视图,允许以键集、值集或键-值映射关系集的形式查看某个映射的内容。
3. Map 映射顺序。有些实现类,可以明确保证其顺序,如 TreeMap;另一些映射实现则不保证顺序,如 HashMap 类。
4. Map 的实现类应该提供2个“标准的”构造方法:第一个,void(无参数)构造方法,用于创建空映射;第二个,带有单个 Map 类型参数的构造方法,用于创建一个与其参数具有相同键-值映射关系的新映射。实际上,后一个构造方法允许用户复制任意映射,生成所需类的一个等价映射。尽管无法强制执行此建议(因为接口不能包含构造方法),但是 JDK 中所有通用的映射实现都遵从它。
版权声明:本文为JAVASCHOOL原创文章,未经本站允许不得转载。